Flatness Preserves Instruction Following in
Vision-Language-Action Models
Abstract
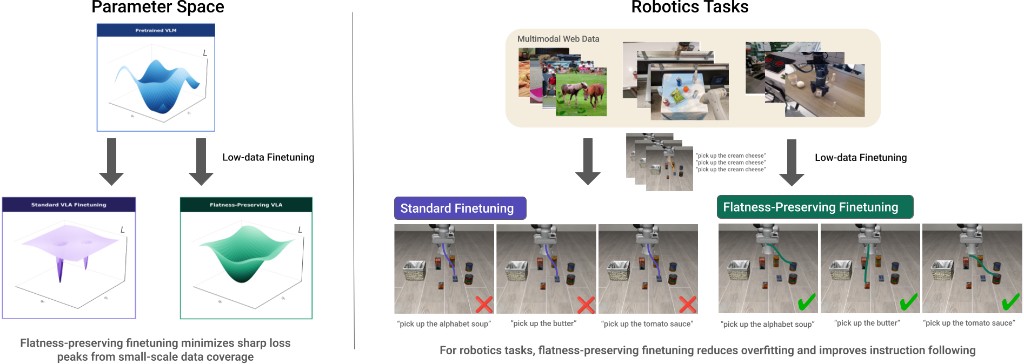
Vision-language-action (VLA) models have the potential for open-world generalization by leveraging pretrained vision-language representations, yet downstream finetuning on limited robot data often degrades these representations, leading to brittle policies that ignore language instructions in favor of visual shortcuts, a failure mode we term instruction blindness. We hypothesize that standard finetuning with limited data applies gradients to a sparse set of points, which manifests as a sharp loss landscape with high-curvature minima. We propose to address this directly through flatness-preserving optimization while finetuning on the exact same data, where learning a flatter landscape results in a model more robust to perturbations in the weight space. Specifically, we demonstrate that simply applying sharpness-aware minimization (SAM) during VLA finetuning significantly improves instruction following by over 60% across multiple simulation and real-world benchmarks without additional data, architectural modification, or retraining. We further analyze the effect of selective sharpness, quantify its effects, and show that our approach is complementary to existing guidance techniques.
Video
Method
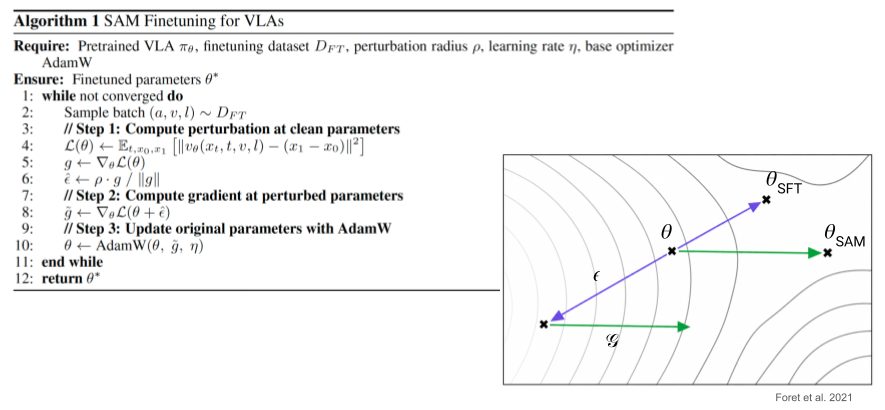
Inspired by prior work in the ML and NLP fields showing the connection between flatness and generalization, we leverage sharpness-aware minimization (SAM) optimization during VLA finetuning. SAM is a bilevel optimization technique to learn flatter minima explicitly by seeking parameters in neighborhoods with uniformly low loss. At each training step, SAM takes a step towards perturbed parameters with the highest loss within a ρ-neighborhood, calculates the gradient at the perturbed parameters, then uses this gradient to take the gradient descent step at the original parameters.
Results
Broadly, we are interested in understanding: RQ 1) Do the generalization benefits of SAM transfer to VLA models, specifically by mitigating instruction blindness? RQ 2) Is a flatter manifold indicative of better language following? RQ 3) How should SAM be applied on a large-parameter VLA model? RQ 4) Does SAM work in combination with other instruction-following techniques?
Simulation Results
We finetune a pre-trained VLA model using SAM on the LIBERO training suite and benchmark language-following ability compared with a variety of baselines finetuned on the exact same (or more) data. We evaluate the method on three counterfactual benchmarks where alternate task instructions are paired with training scenes: LIBERO-PRO Task, LIBERO-CF, and LangGap. In total, the evaluation in simulation consists of 138 new tasks evaluated zero-shot with 50 rollouts each. We find that finetuning with SAM significantly improves instruction following accuracy across all three benchmarks over all baselines.
Table 1: Success rate (%) across LIBERO-PRO and LangGap. † indicates the result is as reported in the original paper.
| Method | LIBERO-PRO | LIBERO-LangGap | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Goal | Spatial | Object | Long | Avg | Goal | Spatial | Object | Avg | |
| Vanilla VLAs | |||||||||
| OpenVLA-OFT | 0.0 | 3.8 | 1.6 | 0.0 | 1.4 | 0.0 | 0.0 | 0.0 | 0.0 |
| π₀.₅ | 25.0 | 52.8 | 11.6 | 17.0 | 26.6 | 30.0 | 5.9 | 37.7 | 24.5 |
| Factorized Guidance | |||||||||
| BayesVLA† | — | — | 10.0 | — | 10.0 | — | — | — | — |
| π₀.₅ cfg | 25.4 | 49.4 | 28.0 | 18.0 | 30.2 | 43.8 | 8.5 | 35.8 | 29.4 |
| Data Augmentation | |||||||||
| π₀.₅ LangGap† | — | — | — | — | — | 27.2 | 10.2 | 37.0 | 24.8 |
| Representation Regularization | |||||||||
| π₀.₅ LORA | 11.0 | 11.0 | 5.0 | 0.0 | 6.75 | 0.2 | 0.2 | 0.3 | 0.2 |
| π₀.₅ SAM (Ours) | 43.4 | 54.2 | 42.4 | 30.6 | 42.6 | 56.7 | 19.7 | 48.7 | 41.7 |
Table 2: Success rate (%) across LIBERO-CF. † indicates results reported in LIBERO-CF.
| Method | CF-Spatial | CF-Object | CF-Long | CF-OOD | Average |
|---|---|---|---|---|---|
| OpenVLA-OFT† | 1.1 | 0.0 | 0.2 | 0.1 | 0.4 |
| OpenVLA-OFT CAG† | 7.9 | 0.0 | 0.4 | 0.1 | 11.3 |
| π₀.₅† | 24.4 | 5.8 | 15.8 | 6.9 | 13.2 |
| π₀.₅ cfg | 26.8 | 19.6 | 52.6 | 46.0 | 36.3 |
| π₀.₅ CAG† | 31.6 | 18.0 | 26.7 | 10.3 | 21.7 |
| π₀.₅ LORA | 10.3 | 0.0 | 12.4 | 0.0 | 5.7 |
| π₀.₅ SAM (Ours) | 55.3 | 26.2 | 55.4 | 54.1 | 47.8 |
A number of rollouts for both the baseline VLA (π₀.₅ checkpoint finetuned on LIBERO) and the VLA finetuned with SAM are shown for LIBERO-PRO Task instructions. The VLA finetuned with SAM succeeds at grounding the correct object to grasp while the default VLA often fails.
Pick the butter and place it in the basket
π₀.₅

π₀.₅ + SAM

Pick the cream cheese and place it in the basket
π₀.₅

π₀.₅ + SAM

Pick the orange juice and place it in the basket
π₀.₅

π₀.₅ + SAM

Pick the salad dressing and place it in the basket
π₀.₅

π₀.₅ + SAM

Real-World Results
We design a set of real-world evaluations using the DROID setup for five pick-and-place tasks. For each scene, we collect demonstrations for an in-domain task and induce visual bias by only collecting demonstrations for that one task per scene layout. We then finetune a VLA on this biased dataset with and without SAM and evaluate with a counterfactual language instruction for each scene. We further test the robustness of the language following capability by introducing an unseen background perturbation for three tasks.
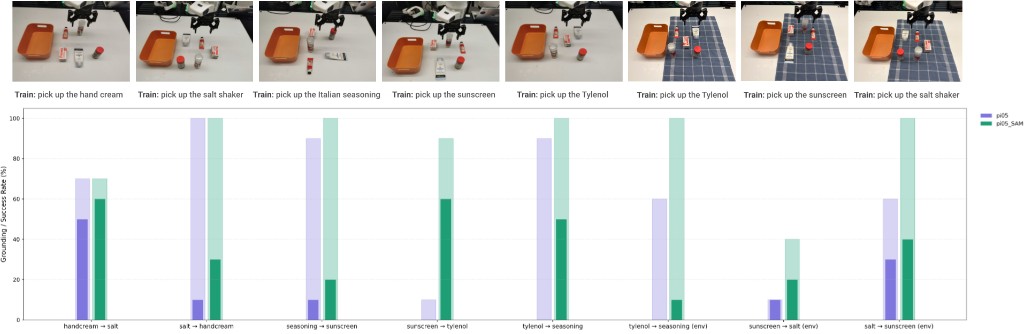
Real-world results on counterfactual instructions at inference time with limited demonstration data. Each bar shows the grounding rate (translucent) and task success rate (solid). π₀.₅ + SAM improves both grounding and task success on counterfactual instructions, including with background perturbations.
π₀.₅
π₀.₅ + SAM
Rollout video coming soon.
Unseen background perturbation
π₀.₅
π₀.₅ + SAM
Rollout video coming soon.
Representation Analysis
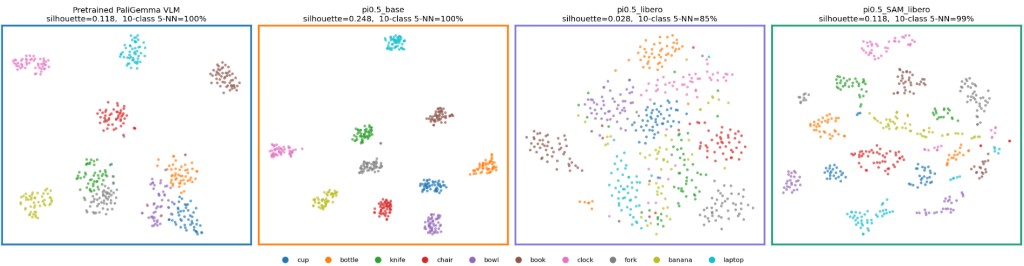
We conduct a probe on the vision-language embedding space to verify the effect of SAM on the representations, using the COCO dataset and visualize using a t-SNE plot. As seen from the figure, for the pretrained VLM and even the base VLA model, the object categories form coherent semantic clusters. In contrast, the representations are disrupted after standard finetuning on LIBERO, but are then implicitly remedied by finetuning with SAM.
Subsequently, we quantify the curvature of the landscape with a sharpness metric and the maximum eigenvalue of the Hessian λmax. We use a Lanczos approximation to calculate this and verify that the sharpness value and max. eigenvalue of the Hessian are both lower when finetuning with SAM.
Table 3: Sharpness and max. eigenvalue of the Hessian
| S (↓) | λmax (↓) | |
|---|---|---|
| π₀.₅ | 0.012 | 0.93 |
| π₀.₅ SAM | 0.005 | 0.52 |
BibTeX
@inproceedings{zhang2026flatness,
title={Flatness Preserves Instruction Following in Vision-Language-Action Models},
author={Zhang, Haochen and Bisk, Yonatan},
booktitle={Under Review},
year={2026},
url={https://arxiv.org/abs/2606.23641}
}